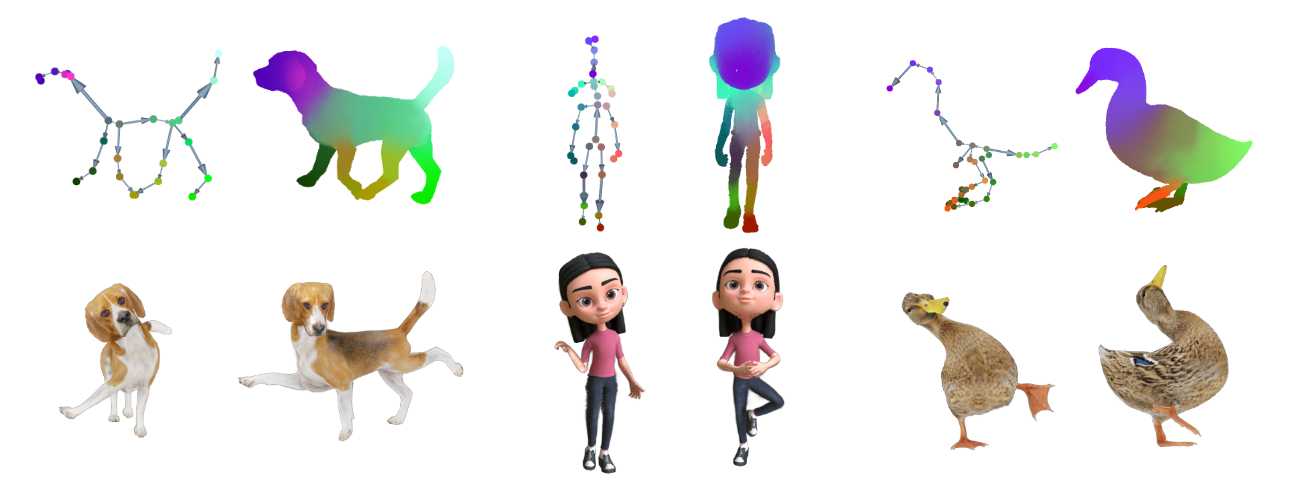
Abstract
This paper considers the problem of modeling articulated objects captured in 2D videos to enable novel view synthesis, while also being easily editable, drivable, and re-posable. To tackle this challenging problem, we propose RigGS, a new paradigm that leverages 3D Gaussian representation and skeleton-based motion representation to model dynamic objects without utilizing additional template priors. Specifically, we first propose skeleton-aware node-controlled deformation, which deforms a canonical 3D Gaussian representation over time to initialize the modeling process, producing candidate skeleton nodes that are further simplified into a sparse 3D skeleton according to their motion and semantic information. Subsequently, based on the resulting skeleton, we design learnable skin deformations and pose-dependent detailed deformations, thereby easily deforming the 3D Gaussian representation to generate new actions and render further high-quality images from novel views. Extensive experiments demonstrate that our method can generate realistic new actions easily for objects and achieve high-quality rendering.
Method
Pipeline
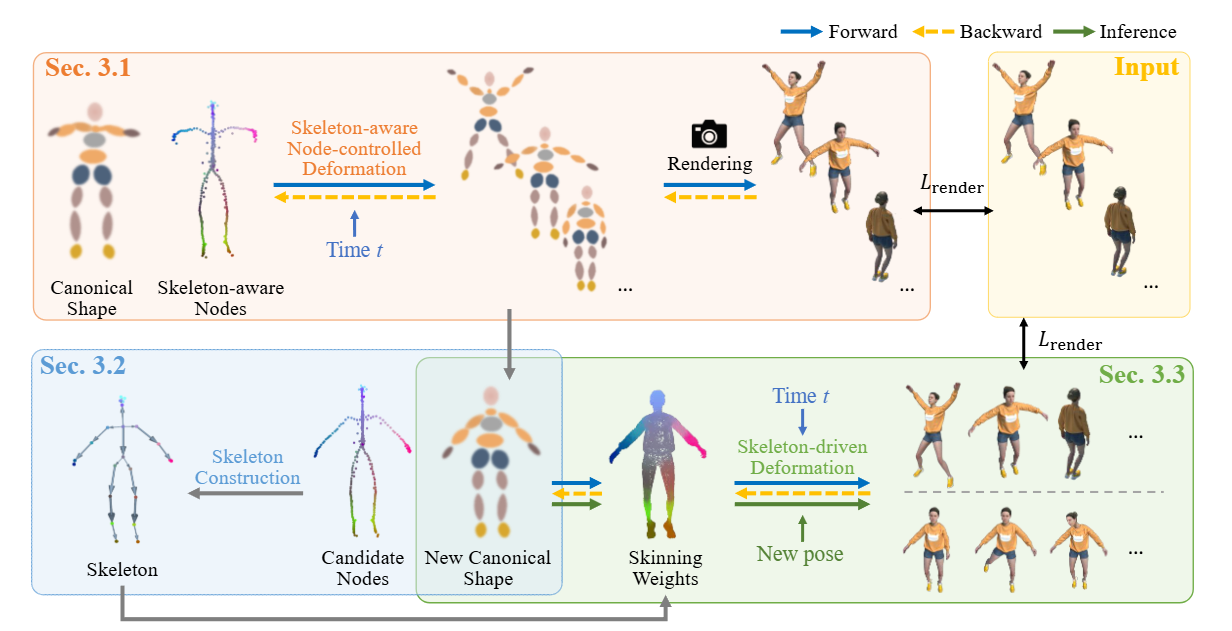
Illustration of the proposed RigGS, which can reconstruct articulated objects from videos and allow for easy editing and interpolation of object motion while supporting high-quality real-time rendering for these creative poses.
Video
BibTeX
@inproceedings{yao2025riggs,
author = {Yao, Yuxin and Deng, Zhi and Hou, Junhui},
title = {RigGS: Rigging of 3D Gaussians for Modeling Articulated Objects in Videos},
booktitle = {CVPR},
year = {2025},
}